
Τι είναι το Search Engine Optimization;
Πολλοί από εμάς έχουμε ακούσει το όρο Search Engine Optimization (SEO). Αρκετοί γνωρίζουν ότι έχει να κάνει με την αναζήτηση στο Google, δίχως όμως να ξέρουν τι ακριβώς είναι.
Το Search Engine Optimization αποτελεί μία διαδικασία κατά την οποία ένας ιστότοπος προσαρμόζεται με τρόπο τέτοιο ώστε να είναι πιο φιλικός προς τις μηχανές αναζήτησης. Υπάρχουν αρκετοί παράγοντες, ο καθένας με τη δική του βαρύτητα και διαδικασία βελτιστοποίησης.
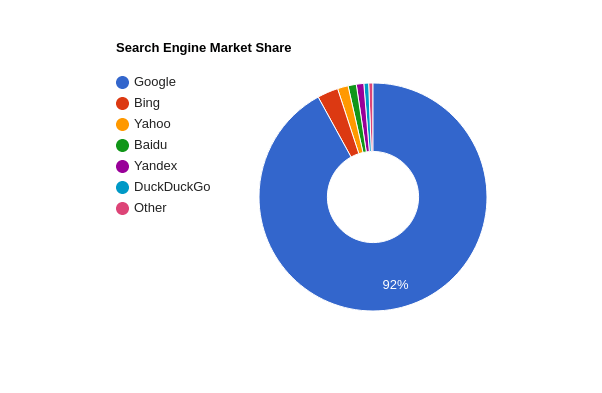
Το Google, αν και η μεγαλύτερη και σημαντικότερη, δεν είναι η μοναδική μηχανή αναζήτησης. Υπάρχουν πολλές ακόμη, οι οποίες λειτουργούν με την ίδια φιλοσοφία γύρω από το SEO. Οι κορυφαίες μηχανές αναζήτησης είναι:
| Όνομα | Ποσοστό Χρηστών |
|---|---|
| 92.01% | |
| Bing | 2.96% |
| Yahoo! | 1.51% |
| Baidu | 1.17% |
| Yandex | 1.06% |
| DuckDuckGo | 0.68% |
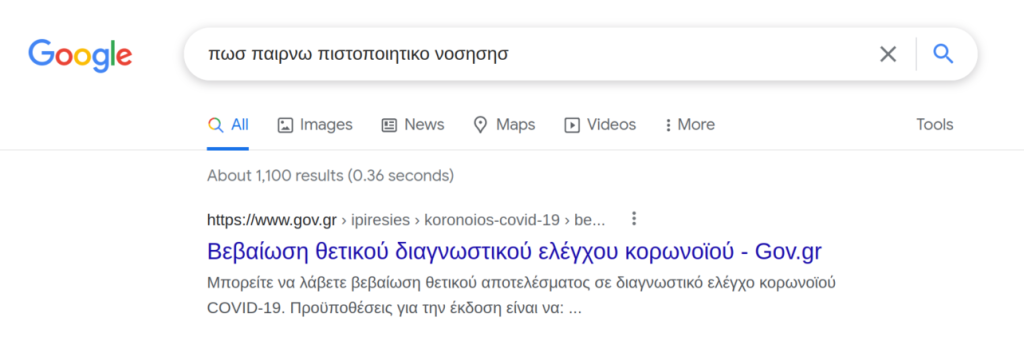
Πώς δουλεύουν οι μηχανές αναζήτησης;
Πρωτού δούμε τους τρόπους με τους οποίους επιτυγχάνεται το Search Engine Optimization, πρέπει να δούμε πώς δουλεύουν οι ίδιες οι μηχανές αναζήτησης.
Καμία μηχανή αναζήτησης δεν ψάχνει για αποτελέσματα τη στιγμή που πραγματοποιούμε μια αναζήτηση. Κάτι τέτοιο θα ήταν αδύνατο, καθώς απαιτούνται τεράστιοι πόροι ενέργειας, υπολογιστικής ισχύος και χρόνου. Αυτό που κάνουν ονομάζεται Indexing.
Τι είναι το Indexing;
Στα Αγγλικά, η λέξη index όσον αφορά μία βάση δεδομένων σημαίνει ευρετήριο. Τα ευρετήρια στις βάσεις δεδομένων βοηθούν έναν υπολογιστή να βρει τις πληροφορίες που ψάχνει πολύ γρηγορότερα, όπως ακριβώς ένα κανονικό ευρετήριο βοηθά έναν άνθρωπο να βρει αυτό που ψάχνει γρηγορότερα, αντίστοιχα.
Οι μηχανές αναζήτησης κρατούν αποθηκευμένα στους servers τους όλα τα δεδομένα από τις ιστοσελίδες που έχουν εντοπίσει και, χάρη στα ευρετήριά τους, όποτε ένας χρήστης πραγματοποιεί μία αναζήτηση, του παρουσιάζουν τα αντίστοιχα αποτελέσματα σε χρόνο μηδέν.
Προκειμένου, όμως, να αποθηκευθούν όλες αυτές οι πληροφορίες από τα εκατομμύρια sites που υπάρχουν σήμερα, οι μηχανές αναζήτησης πρέπει να τα επισκεπτούν… ένα προς ένα! Αυτό ονομάζεται Web Crawling.
Τι είναι το Web Crawling;
Προφανώς, το να επιστρατευθούν ορισμένοι χρήστες και να αποθηκεύουν τις πληροφορίες από όλες τις ιστοσελίδες είναι αδύνατο. Αυτό γίνεται αυτόματα από ηλεκτρονικούς υπολογιστές.
Η λέξη crawl στα Αγγλικά σημαίνει μπουσουλάω. Κατά το Web Crawling οι μηχανές αναζήτησης ελέγχουν όλα τα στοιχεία μίας ιστοσελίδας και προωθούν όσα χρειάζεται για Indexing.
Οι σύνδεσμοι, εσωτερικοί και εξωτερικοί, σε μία σελίδα, βοηθούν τους web crawlers να βρίσκουν όλο και περισσότερα στοιχεία. Ειδικά οι εξωτερικοί σύνδεσμοι, βοηθούν να ανακαλύπτονται νέες ιστοσελίδες γρηγορότερα.
Τι είναι το Ranking;
Το Web Crawling συνεπάγεται ένα τεράστιο όγκο δεδομένων. Προκειμένου οι χρήστες να μη “χάνονται” μέσα στα αποτελέσματα, οι μηχανές αναζήτησης φροντίζουν τα σχετικά αποτελέσματα να εμφανίζονται στην κορυφή. Αυτό ονομάζεται Ranking.
Υπάρχει ένα πολύ καλό σχετικό ανέκδοτο: “Αν θες να κρύψεις κάτι και να μην το βρει ποτέ κανείς, κρύψ’το στη δεύτερη σελίδα των αποτελεσμάτων αναζήτησης του Google“. Είναι αλήθεια ότι το Google είναι η καλύτερη μηχανή αναζήτησης όσον αφορά την ταξινόμηση των αποτελεσμάτων. Αυτό οφείλεται σε δύο, κυρίως, λόγους:
- Έχει το μεγαλύτερο όγκο δεδομένων (data) όσον αφορά τα αποτελέσματα που επιλέγουν οι χρήστες ανά περιοχή, ηλικία κλπ.
- Δημιουργεί ένα μοναδικό προφίλ με τις προτιμήσεις του κάθε χρήστη και το αξιοποιεί προκειμένου να εμφανίσει στην κορυφή πιο προσαρμοσμένα αποτελέσματα.
Ο δεύτερος λόγος έχει, βέβαια, και ένα μεγάλο αρνητικό. Το Google γνωρίζει όλα όσα ψάχνει ο κάθε χρήστης. Δε λαμβάνει στοιχεία μόνο από τις αναζητήσεις, αλλά και από το Android κινητό, καθώς και από όλες τις ιστοσελίδες που έχουν επιτρέψει στην εταιρία να ιχνηλατούν (να κάνουν trackick) τους χρήστες.
Μία εναλλακτική λύση είναι το DuckDuckGo. Είναι η μεγαλύτερη μηχανή αναζήτησης που δεν αποθηκεύει κανένα εξατομικευμένο δεδομένο, διατηρώντας την ανωνυμότητα του χρήστη. Φυσικά, αυτό που μας ενδιαφέρει περισσότερο για το SEO, είναι το Google, καθώς πρόκειται για ένα “σχεδόν μονοπώλειο”.
Όλη η διαδικασία του Search Engine Optimization γίνεται προκειμένου να επιτευχθεί καλύτερη κατάταξη στις μηχανές αναζήτησης.
Πώς επιτυγχάνεται το SEO;
Υπάρχουν πάρα πολλοί παράγοντες που μπορούν να επηρεάσουν τη φιλικότητα προς τις μηχανές αναζήτησης και την ταξινόμηση. Σύμφωνα με τη μηχανή Lighthouse, οι βασικοί είναι οι ακόλουθοι:
Viewport meta tag
<meta name="viewport" content="width=device-width,initial-scale=1.0">Τα meta tags είναι κομμάτγια πληροφορίας σε μία ιστοσελίδα και η ονομασία τους προκύπτει από το metadata. Το viewport meta tag χρησιμέυει για να μπορεί να γίνει μία ιστοσελίδα responsive.
Τίτλος
Ο τίτλος βοηθάει το χρήστη να κατανοήσει το τι περιέχει η σελίδα και οι μηχανές αναζήτησης βασίζονται πάρα πολύ σε αυτόν προκειμένου να κρίνουν εάν η σελίδα είναι σχετική με την αναζήτηση του χρήστη.
Description meta tag
<meta name="description" content="Αυτό είναι ένα παράδειγμα περιγραφής σελίδας.">
Η περιγραφή meta μπορεί να συμπεριληφθεί στα αποτελέσματα αναζήτησης ως μία περίληψη του περιεχομένου.
Επιτυχές HTTP status code
Οι σελίδες που δεν επιστρέφουν επιτυχές HTTP status code μπορεί να μην καταχωρισθούν επιτυχώς από τις μηχανές αναζήτησης.
Οι σύνδεσμοι συνοδεύονται από περιγραφή
Οι σύνδεσμοι (links) πρέπει να συνοδεύονται από κείμενα τα οποία περιγράφουν (σε ένα βαθμό) τη σελίδα στην οποία παραπέμπουν. Για παράδειγμα, ο παρακάτω κώδικας είναι αποδεκτός:
<p>Για να μάθετε τι κάνει μια ιστοσελίδα πραγματικά γρήγορη, <a href="/what-makes-a-website-trully-fast">πατήστε εδώ</a>.</p>Το αποτέλεσμα του παραπάνω κώδικα είναι αυτό:
Για να μάθετε τι κάνει μια ιστοσελίδα πραγματικά γρήγορη, πατήστε εδώ.
Οι σύνδεσμοι είναι crawlable
Προκειμένου οι μηχανές αναζήτησης να ανακαλύψουν όλες τις σελίδες ενός ιστοτόπου, πρέπει να μπορούν να έχουν πρόσβαση σε όλους τους συνδέσμους κατά το web crawling. Οι έγκυροι σύνδεσμοι δείχνουν πάντονε σε κάποιο url.
Το Indexing επιτρέπεται
Προκειμένου οι μηχανές αναζήτησης να κάνουν index (να καταχωρίσουν) μία σελίδα, πρέπει να έχουν την άδεια του ιδιοκτήτη. Για να αποτρέψετε μία μηχανή αναζήτησης να κάνει index σε μία συγκεκριμένη σελίδα, προσθέτετε τον παρακάτω κώδικα:
<meta name="robots" content="noindex" />Το robots.txt είναι έγκυρο
Το robots.txt είναι ένα αρχείο το οποίο δείχνει στις μηχανές αναζήτησης ποιες σελίδες μπορούν να επισκεπτούν. Εφόσον δεν είναι έγκυρο ή δεν υπάρχει, μπορεί το indexing να μην προχωρήσει σωστά.
Οι εικόνες έχουν περιγραφή alt
Κατά κανόνα, όλες οι εικόνες στις ιστοσελίδες πρέπει να έχουν μία περιγραφή alt. Αυτή, πέραν του ότι εμβανίζεται εφόσον η εικόνα δε φορτώσει, βοηθάει τις μηχανές αναζήτησης να γνωρίζουν τι απεικονίζει η εικόνα. Ακολουθεί περιγραφή κώδικα:
<img alt="Αυτή είναι η περιγραφή της εικόνας" src="my_image.jpg">Οι διαφορετικές εκδόσεις ανά γλώσσα είναι ορισμένες
Πολλές ιστοσελίδες είναι διαθέσιμες σε διαφορετικές γλώσσες. Προκειμένου οι μηχανές αναζήτησης να κάνουν index την κάθε σελίδα στην κάθε γλώσσα και με το σωστό τρόπο, πρέπει αυτές να έχουν οριστεί. Ακολουθεί παράδειγμα κώδικα:
<link rel="alternate" hreflang="el" href="https://getawebsite.gr/" />
<link rel="alternate" hreflang="en" href="https://en.getawebsite.gr/" />
<link rel="alternate" hreflang="de" href="https://de.getawebsite.gr/" />Το canonical link είναι ορισμένο
Όταν πολλές σελίδες έχουν παρόμοιο ή ίδιο περιεχόμενο, οι μηχανές αναζήτησης κατά το web crawling τις καταγράφουν ως διπλοεγγραφές. Οι μηχανές αναζήτησης επιλέγουν μία ως την “κανονική” (ή βασική). Τα canonical links ενημερώνουν τις μηχανές αναζήτησης για το ποια σελίδα είναι η “κανονική”, ώστε να εμφανίζεται στα αποτελέσματα αναζήτησης. Ένας τρόπος να επιτευχθεί αυτό είναι ο παρακάτω:
<link rel="canonical" href="https://getawebsite.gr" />Η ιστοσελίδα αποφεύγει τα plugins
Πολλες φορές, οι μηχανές αναζήτησης δε μπορούν να κάνουν index το περιεχόμενο που βασίζεται σε plugins όπως η Java ή το Flash. Αυτό σημαίνει ότι ίσως το περιεχόμενο αυτό να μην εμφανιστεί στα αποτελέσματα αναζήτησης. Η καλύτερη λύση είναι να μη γίνεται η χρήση αυτών, καθώς δεν είναι πλέον απαραίτητα.